Linux: io_uring #60
Labels
No Label
bug
duplicate
enhancement
help wanted
invalid
question
security
wontfix
No Milestone
No Assignees
1 Participants
Notifications
Due Date
No due date set.
Dependencies
No dependencies set.
Reference: AuroraSupport/AuroraRuntime#60
Loading…
Reference in New Issue
Block a user
No description provided.
Delete Branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Implement support for io_uring in place of the current aio if the kernel version is over 5.19
5.5* min
or linux performance can eat shit and we can go back to looking into freebsd support like i wanted to
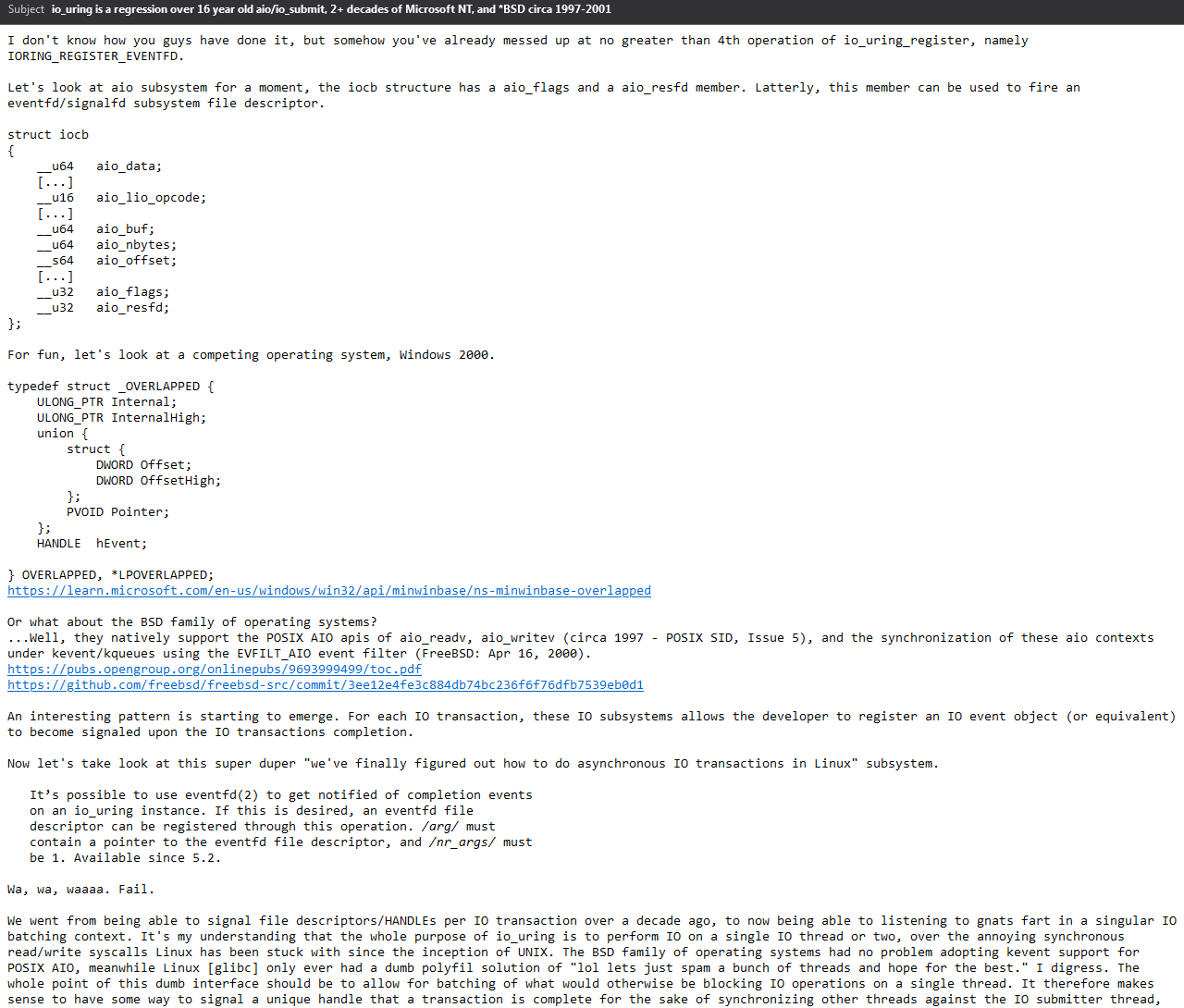
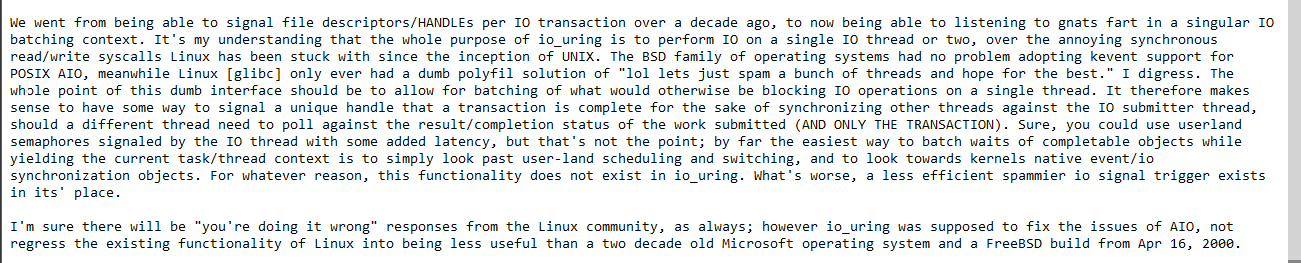
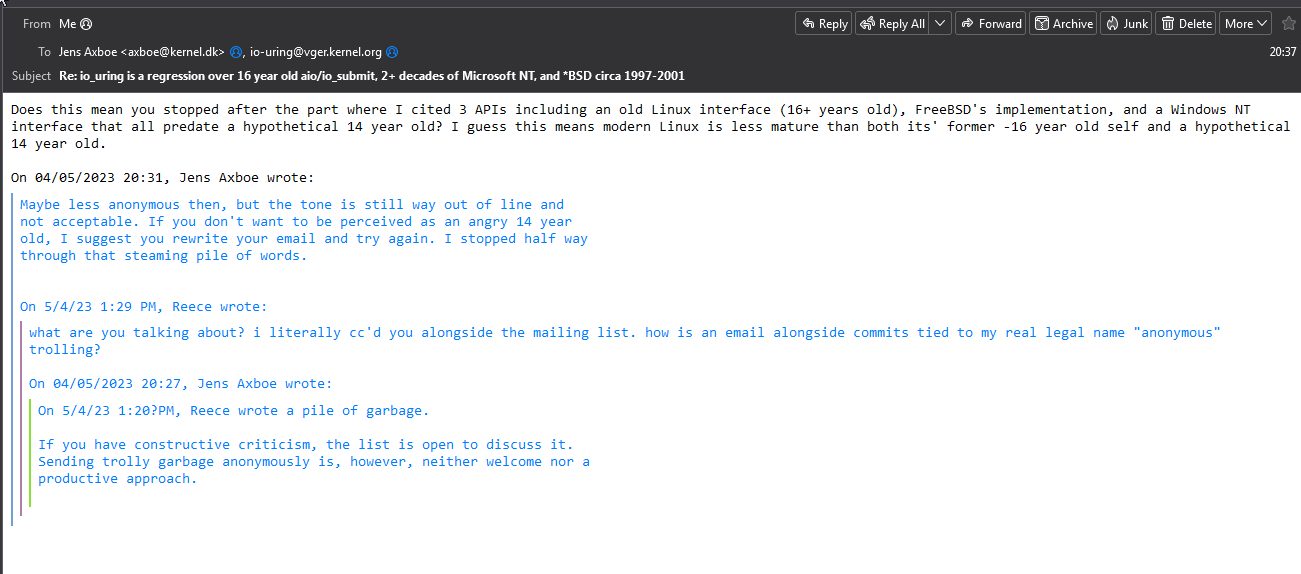
What actual schizos
> says my name
> "ANONYMOUSLY TROLLING" from a unique email
ok. Will block Linux development until these retards write an IO subsystem worth half a damn
https://twitter.com/axboe/status/1654211976191700992
rent-free / removing linux support (?).
imagine being almost 50 subtweeting people you called 14 by email bc they called your interface a regression. ironically, aurora runtime and other components will always be lengther than any of his linux kernel contributions. talk about productivity copium coming from a dude who works at a company that only values cmakelist contributions
similar quirks exist under windows https://learn.microsoft.com/en-GB/troubleshoot/windows/win32/asynchronous-disk-io-synchronous#asynchronous-io-still-appears-to-be-synchronous
identical quirks include: block-on-metadata update, unsupported file system or file system feature
all i see is "muh syscall overhead" copium, when in reality linux programs, if not optimized, hammer syscalls all the god damn time. as if a few calls into the kernel per io loop is that much of a concern. i fail to see how using ring buffers are even an optimization. its not like physical hardware just went "lol heres a ring buffer," now we no longer need to fire msi-x interrupts and deal with other fencing mechanisms. we still need those submit/forced read barriers. so far as optimizing 'work is already done, you know this, plz no expensive sync' conditions are concerned, we dont need to enter the kernel to spin-poll or try-poll for completion events under either subsystem. not to mention io_urings write head sync is no different than our batched submit. this "hurrhurr you need a faster cpu to saturate the IO device" just sounds like theoretical copium of those naively assuming "io_uring = no/little syscalls = more time in userland = faster." maybe im being too kind calling dumb cunts, who think a syscall is a context switch in the traditional sense of storing a context for lengthy yield, "naive" (as opposed to simply pushing a few registers, either in hardware or in software, to do a quick task in a privileged state under a foreign ABI)
the last remaining point is, "hurdur why cant i do arbitrary buffered io in the kernel." go map a file and let the page faults, swap lock interface, and paging configuration deal with it. done. im surprised arbitrary file access isn't a userland concept given a crt or runtime abstraction of mmap/file sections or unbuffered direct io in the worst case. it cannot be understated how many limitations there are in every kernels async/overlapped io subsystem. async truly is a concept reserved for seeking in large blocked database structures and sequential piping of data, in the best case scenario; it's not a replacement for the glibc hack of "threads go brrr" or libuvs philosophy of, well, "threads go brr"
on that note, why dont we have a configurable buffered direct-io/mmap file stream with callbacks and configurable cache pages? why not share that interface with a seekable reader interface adapter while we're at it? seems like a useful feature to have. it'd beat what other runtimes consider a "buffered" [input/output] stream
more on topic, if we can already do all the io ops we care about asynchronously on a single thread, namely non-blocking socket connect, non-blocking socket acceptance, polled read, polled write, file block read, file block write; then why the hell should we even care for linux's
lets see
selectepollaio/io_submitio_uring
linux's 4th non-blocking mechanism intended to increase io performance... 4th attempt and linux is still not as good as the BSD and NT family of operating systems. NT got it on their first attempt, and BSD on their first real implementation of kevent/kqueue alongside POSIX SID: Issue 5.
any performance improvement in io_uring is probably placebo or that of microbenchmarkers trying to prove themselves in a particular niche. maybe they intentionally crippled aio and have no intention of improving it now they have a new shiny toy to shill. idk. either way, its not enough to justify refactoring away (sometimes shared) loop sources of io transactions.
some more objective data: https://atlarge-research.com/pdfs/2022-systor-apis.pdf
you have to configure the kernel to employ the ideology of "threads go brrrr" (the one thing i cant fucking stand), just to get close to the performance of a highly optimized driver and software development kit centered around NVMe drives. we may as well employ an a hidden spdk abstraction, should the need arise for what i suppose would be a highly niche academic use case.
overall, we're talking like 133k/ops under aio as opposed to 171k/ops @ 64 batches/submission
latency is basically neck and neck
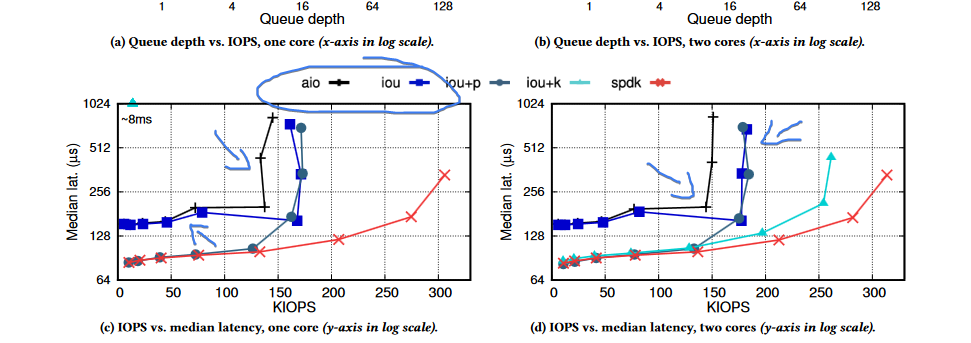
to go any faster, you need to start thinking about tweaking the queue, spamming kernel threads, and other bullshit inappropriate for our layer of abstraction. what are we to do, start spamming kernel threads for each singular userland thread with a TLS IO context to get close to an SDK that's actually optimized for NVMe I/O? why the hell cant they just make an optimized io subsystem and interface that just werks like NT?
everything points towards, just use spdf if you care about io performance, for, i dont know, particle and fluid simulation in userland via simd optimizations?
casual use cases are neck and neck, if not equal
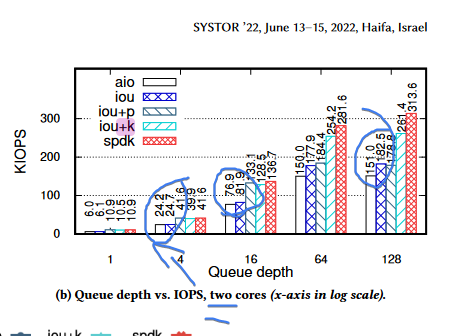
aio is fine. use spdfs interfaces directly if u actually need to optimize for niche high performance disk io. linshit interfaces will never be good enough for high performance io. or in the words of the aforementioned paper,
"but ultimately it cannot match the throughput and scalability of SPDK (Figure 5). Finally, iou is consistently the worst-performing configuration of io_uring, suggesting that polling is one of the key ingredients to unleashing the full potential of io_uring"
i doubt any aurt user will get close to hitting these constraints.
also note there are diminishing returns with spamming the io queue. bandwidth != io/ops. 6 (~1=QD) * 64 ~= 300. not even QD=128 gets this close.
i also couldnt think of a reason why we would need hundreds of thousands of disk io operations per second. sure, i could comprehend a really shitty database needing to serve unindexed data at a high rate, but even then i cannot mentally comprehend more than tens of thousands of operation per second. aio, per thread, doesn't fall off until an order of mangitude ahead of that. i dont even think this runtime is optimized for such high volume of requests; i care more about higher bandwidth client applications. there's real no use case where these marginal differences between apis matter to us... maybe it matters to the one dude trying to prove pi while squatting in an NSA cray supercomputing basement, but not to us
now that i say this, 6k op/s thread * n threads... now what these redditors were saying makes sense. aio might be able to out perform io_uring without a ton of kernel threads doing blocking polls behind the scenes
6k op/s thread scales upto QD=2/2 batched ops, to peak at around 12.71GB/s of throughput
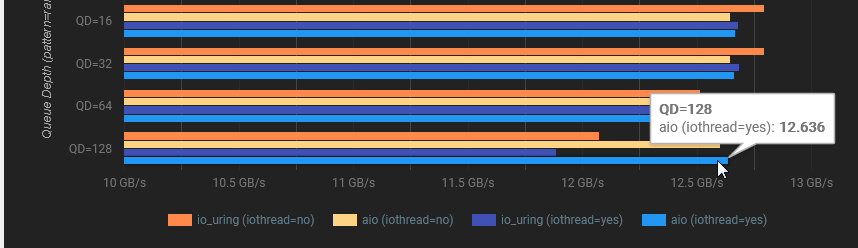
hammering io_uring with QD=32/32 [!!!] batched ops per tick, barely gets past 12.795GB/s
https://kb.blockbridge.com/technote/proxmox-aio-vs-iouring/
exactly what i predicted... it literally does not matter out side of "LOOOOOK MOM I WROTE A BENCHMARK." it only matters if you're a brainlet ex-oracle developer spamming the disk with an unnecessary amount of arbitrary and tiny db access operations
sperging aside, block sizes and worker pool (or multiple overlapped submission) sizes matter. the underlying interface does not. only spdf scales. everything else is in the same ballpark. if anything, io_uring does not scale to our use case.
Reece, [20/07/2023 19:33] how is an io interface responsible for any vulnerability
Reece, [20/07/2023 19:33] but still
Reece, [20/07/2023 19:34] imagine an io interface costing so many developer resources and bug bounty payouts that its considered unusable